Exploitez l’IA sans compromettre vos données !

Vous êtes-vous déjà demandé comment protéger la confidentialité de vos données privée ou celles de votre entreprise dans un monde de plus en plus centré sur l’utilisation de services centralisé (API) ? Vous vous interrogez sur la manière de bénéficier des avantages de l'IA tout en préservant la sécurité des données ? Dans cet article, nous aborderons l'utilisation de l'IA en local pour renforcer la confidentialité des données. En explorant cette approche, vous découvrirez comment les modèles d'IA locaux offrent un contrôle accru, une sécurité renforcée et une personnalisation optimale, vous permettant ainsi d'exploiter les avantages de l’IA, et ce en toute sérénité.
IA local pour une confidentialité renforcée
Avec l’utilisation accrue des services centralisés comme OpenAI, la confidentialité est devenue une préoccupation majeure pour les individus et les entreprises. L'intelligence artificielle est connue pour être un puissant outil pour traiter des données, mais elle suscite également des inquiétudes concernant la confidentialité. Une fuite de données peut avoir des répercussions graves, allant de la perte de confiance des clients à des poursuites judiciaires coûteuses et à des dommages irréparables pour la réputation de l'entreprise.
En utilisant des modèles d'IA locaux, les entreprises peuvent réduire considérablement le risque de fuites de données en évitant la transmission de données sensibles vers des serveurs distants. En traitant et en stockant les données localement, les entreprises conservent un contrôle total sur la sécurité et la confidentialité de leurs informations, réduisant ainsi le risque d'accès non autorisé et de compromission des données.
Imaginez une entreprise médicale travaillant sur des données de patients. Plutôt que de partager ces informations avec des services cloud externes, elle peut utiliser des modèles d'IA locaux pour analyser les données directement sur site, préservant ainsi la confidentialité des patients et se conformant aux réglementations strictes en matière de protection des données, telles que le RGPD.
Le renforcement de la confidentialité des données grâce à l'utilisation de l'IA en local offre donc une protection essentielle contre les conséquences néfastes d'une fuite de données pour une entreprise. En adoptant cette approche, les entreprises peuvent mieux protéger leurs données sensibles et prévenir les dommages financiers, juridiques et réputationnels potentiellement catastrophiques associés aux violations de la confidentialité des données.
Modèles d'IA Locaux VS Services en ligne
Les modèles d'IA locaux permettent l'exécution de modèles d’IA divers comme les LLM directement sur des serveurs locaux (On-Premise) ou un serveur cloud privés, sans recourir à une infrastructure externalisée (cloud). Cette approche réduit la dépendance à l'égard des fournisseurs de cloud computing et des services tiers, offrant ainsi une plus grande autonomie et un contrôle accru sur les données.
L'un des grands avantages des modèles d'IA locaux est leur accessibilité croissante. Depuis la sortie de chatGPT le 30 novembre 2022, de nombreux modèles Open Source ont vu le jour et gagnent en performance chaque jour, les rapprochant de plus en plus du modèle original utilisé par chatGPT. Parmi ceux-ci, nous pouvons citer Mistral-7B, un LLM entraîné par l’entreprise française MistralAI (cocorico !) faisant partie des modèles Open Source actuels les plus performants.
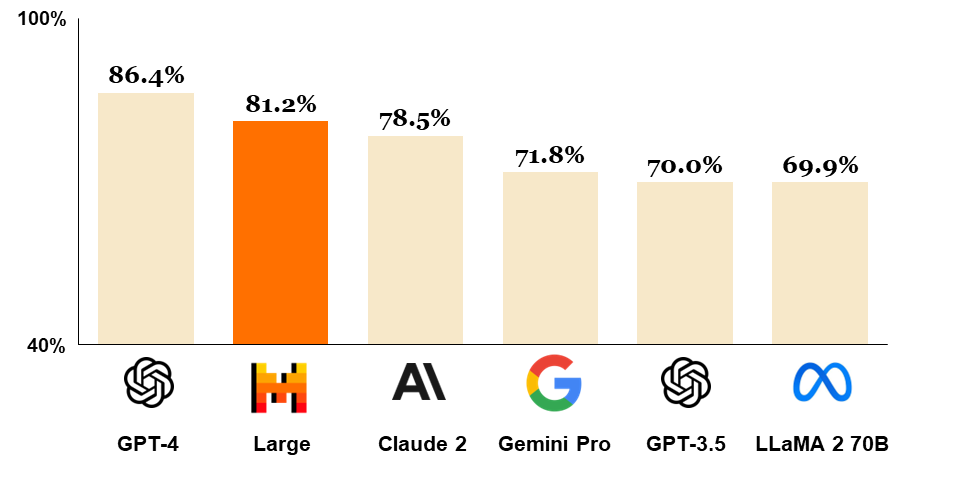
En utilisant des processeurs standards, même les individus et les petites entreprises disposant d'un matériel récent et relativement accessible peuvent expérimenter avec l'IA sans les coûts associés à l'infrastructure cloud ou aux abonnements de services applicatifs (Saas).
Cette démocratisation de l'IA ouvre de nouvelles opportunités pour l'innovation et l’optimisation des processus en entreprise.
IA local pour une personnalisation optimale
Un autre avantage majeur des modèles d'IA locaux est la possibilité de les personnaliser en fonction des besoins spécifiques de chaque entreprise. En s’appuyant sur des modèles génériques préexistants, les organisations peuvent entrainer des solutions sur mesure et les “fine-tuner” à partir de leurs propres données et méthodologies. Cela permet une plus grande précision et pertinence des résultats obtenus par l’IA, tout en garantissant le respect des politiques de confidentialité et la protection du savoir-faire de l’entreprise.
Outre les méthodes traditionnelles telles que l'entraînement et l'ajustement des modèles sur des ensembles de données internes, une solution innovante qui se démarque est l'utilisation de l'architecture RAG (Retrieval Augmented Generation).
L'architecture RAG offre plusieurs avantages distincts pour les entreprises cherchant à personnaliser leurs modèles d'IA. Tout d'abord, elle permet une réduction des coûts important vis à vis d’un fine tuning de modèle classique grâce à la vectorisation des données. Ensuite, il est plus facile d’éditer les éléments que l’IA va utiliser car les données vectorisées sont stocker sur une base de données similaire à celles déjà utilisées en entreprise. Enfin, cette approche garantit la confidentialité des données, car toutes les opérations sont effectuées localement, sans nécessiter le partage ou la transmission de données sensibles à des serveurs externes.
5 facteurs clefs pour choisir son modèle d'IA local
Lorsqu'il s'agit de choisir le modèle d'IA le plus adapté à vos besoins, plusieurs facteurs doivent être pris en compte pour garantir des performances optimales tout en préservant la confidentialité des données.
- Exigences en matière de confidentialité : Le premier facteur essentiel est de choisir un modèle conçu pour fonctionner localement, sans nécessiter la transmission de données vers des serveurs distants. Recherchez des modèles qui garantissent le traitement des données sur site, offrant ainsi un contrôle total sur la sécurité et la confidentialité des informations.
- Type de tâche : Identifiez le type de tâche que vous souhaitez réaliser avec votre modèle d'IA. Est-ce de la classification, de la génération de texte, de la traduction, ou une autre tâche spécifique ? Certains modèles sont spécialisés dans des domaines particuliers, tandis que d'autres sont plus polyvalents.
- Taille du modèle : La taille du modèle peut avoir un impact significatif sur ses performances et ses exigences en termes de ressources. Les modèles plus grands ont tendance à offrir des résultats plus précis, mais nécessitent également plus de puissance de calcul et de mémoire.
- Disponibilité des données et expertise : Considérez également la disponibilité des données dont vous disposez et votre niveau d'expertise en matière d'IA. Certains modèles peuvent nécessiter des ensembles de données spécifiques ou une expertise particulière pour être utilisés efficacement.
- Support et mise à jour : Enfin, assurez-vous de choisir un modèle qui bénéficie d'un bon support de la part de la communauté ou du fournisseur, et qui est régulièrement mis à jour pour garantir des performances optimales et une sécurité continue.
En prenant en compte ces facteurs, vous serez en mesure de choisir le modèle d'IA qui répond le mieux à vos besoins tout en préservant la confidentialité de vos données.
En conclusion : Les avantages de l’IA local
L'adoption de l'IA en local (= les données restent chez vous) représente une avancée significative pour renforcer la confidentialité des données dans un environnement où l'utilisation des services centralisés et des API soulève des préoccupations croissantes quant à la protection de la vie privée et de la propriété intellectuelle. En optant pour des modèles d'IA locaux, les entreprises peuvent non seulement garantir la sécurité de leurs données sensibles, mais également réduire les coûts associés à l'infrastructure cloud et aux abonnements de services tiers.
Chez Synrune, nous nous engageons à tester et mettre en œuvre des solutions d'IA open source et locale pour nos clients qui ont une exigence fortes de confidentialité. De cette manière, nous leur offrons un contrôle total sur l’utilisation de leurs données, tout en contribuant à une approche plus éthique de l'IA.