Comment bien choisir son modèle d’IA générative (le Guide complet)
Avec la prolifération des grands modèles de langage (LLM) disponibles, trouver celui qui correspond à votre cas d'utilisation spécifique peut être une tâche intimidante 😅. Le domaine évolue rapidement, avec de nouveaux modèles et des versions affinées publiés chaque semaine. La liste de LLM est longue et la manière dont ils devraient être appliqués devient rapidement obsolète.
C'est pourquoi il n'est pas logique de décrire chacun des principaux LLM et de désigner leurs forces et faiblesses. Au lieu de cela, dans cet article, nous essaierons de partager des critères que vous pouvez utiliser pour analyser les modèles et vérifier s'ils répondent à vos besoins et contraintes.
Cet article peut servir de guide préliminaire sur la manière d'évaluer un nouveau modèle par rapport à un certain nombre de caractéristiques fondamentales, sur la base desquelles nous vous montrerons également comment comparer les modèles. Les principales caractéristiques d'un LLM que vous devriez considérer sont : la taille, le type d'architecture, les performances sur des benchmarks, les processus de formation et les biais éventuels, ainsi que la licence et la disponibilité du modèle.
👉Les points clés lors de la sélection d’un modèle
Lors de la sélection d'un modèle de langage d'intelligence artificielle, vous devez tenir compte de plusieurs considérations :
✦ Cas d'utilisation prévu
Utiliserez-vous le LLM pour la génération de contenu, la classification, la traduction ou autre chose ? Définir les tâches principales qu'il doit effectuer est essentiel.
✦ Domaine des données
Vos données sont-elles axées sur un domaine spécifique comme la santé, la finance ou les connaissances générales ? Les modèles pré-entraînés sur des données pertinentes donnent de meilleurs résultats.
✦ Exigences en matière de précision
Avez-vous besoin d'une haute précision ou une précision modérée est-elle acceptable ? Les modèles plus grands ont tendance à être plus précis.
✦ Vitesse d'inférence
La latence basse en temps réel est-elle critique ? Les modèles distillés plus petits peuvent inférer plus rapidement.
✦ Besoin de mise à l'échelle
Aurez-vous quelques utilisateurs ou des milliers de requêtes par seconde ? La mise à l'échelle des grands modèles devient coûteuse.
✦ Cloud vs sur site
L'accès à une API cloud offre une commodité tandis que l'installation sur site permet plus de contrôle et de personnalisation.
✦ Contraintes budgétaires
La tarification varie en fonction de l'utilisation des ressources informatiques, des requêtes et de la taille du modèle. Équilibrez le coût par rapport aux fonctionnalités.
✦ Considérations éthiques
Évaluez les biais du modèle, la sécurité et les risques de mauvaise utilisation en fonction de votre cas d'utilisation.
📌Vocabulaires : les termes techniques à connaître
📑Entraînement (Training)
Processus par lequel un modèle de LLM apprend à partir de données d'entraînement pour comprendre et générer du langage naturel. Pendant cette phase, le modèle ajuste ses poids et ses paramètres pour minimiser une fonction de perte spécifique.
📑Fine-tuning (Ajustement fin)
Technique consistant à ajuster un modèle de LLM pré-entraîné sur des données spécifiques à une tâche ou à un domaine particulier. Le fine-tuning permet d'adapter le modèle à des tâches spécifiques tout en conservant les connaissances générales acquises lors de l'entraînement initial.
📑Contexte (Context)
Ensemble d'informations entourant un mot, une phrase ou un passage de texte, qui donne du sens à celui-ci. Les modèles de LLM utilisent le contexte pour comprendre et générer du langage de manière plus précise.
📑Tokens
Unités de base utilisées par les modèles de LLM pour représenter les éléments de texte, tels que les mots, les sous-mots ou les caractères. Chaque token est associé à un vecteur de représentation dans l'espace latent du modèle.
📑Inférence (Inference)
Processus par lequel un modèle de LLM génère des prédictions ou du langage à partir de données en entrée, après avoir été entraîné. L'inférence est souvent utilisée dans des applications en temps réel telles que la traduction automatique ou la génération de texte.
📑Architecture (Architecture)
Structure interne d'un modèle de LLM, comprenant les couches de neurones, les mécanismes d'attention et d'autres composants qui déterminent son fonctionnement et sa capacité à comprendre et générer du langage naturel.
📑Quantification
La quantification est utilisée pour réduire la taille des modèles en convertissant les valeurs de paramètres de haute précision en valeurs de précision inférieure, ce qui permet d'économiser de l'espace de stockage et de mémoire et d'améliorer l'efficacité des calculs. C’est l’équivalent de la compression que l’on connaît pour les fichiers classiques.
Cloud ou Open source ?
L'une des premières décisions à prendre est de déterminer si vous préférez opter pour une solution basée sur le cloud ou si vous préférez une approche open source. Les solutions cloud offrent généralement une facilité d'utilisation et une mise en œuvre rapide, tandis que les solutions open source offrent plus de contrôle et de personnalisation.
💰Coûts
- Cloud : Le déploiement sur le cloud implique généralement des coûts variables en fonction de l'utilisation, tels que les frais de calcul, de stockage et de bande passante. Bien que le cloud offre une mise en œuvre rapide et une évolutivité facile, les coûts peuvent augmenter rapidement avec l'utilisation intensive des ressources.
- Open source : En revanche, le déploiement en open source peut être plus économique à long terme, car il élimine les frais récurrents associés au cloud. Cependant, il peut nécessiter des investissements initiaux plus importants en termes de matériel et de main-d'œuvre pour la configuration et la maintenance du système.
⚙️Flexibilité
- Cloud : Le cloud offre une flexibilité significative en permettant un accès à distance aux ressources informatiques à partir de n'importe où dans le monde. Il permet également de rapidement adapter la capacité de calcul en fonction des besoins, ce qui est particulièrement utile pour les charges de travail variables.
- Open source : En comparaison, le déploiement en open source offre une plus grande liberté dans la personnalisation et la configuration du système, permettant ainsi un contrôle plus fin sur l'infrastructure et les logiciels utilisés. Cela peut être avantageux pour les organisations ayant des exigences spécifiques en matière de sécurité ou de conformité.
🔒Sécurité
- Cloud : Les fournisseurs de services cloud investissent généralement dans des mesures de sécurité robustes pour protéger les données et les ressources de leurs clients. Cependant, la dépendance à l'égard d'un tiers pour la gestion des données peut poser des préoccupations en matière de confidentialité et de conformité réglementaire.
- Open source : En open source, la sécurité dépend de la diligence exercée par l'organisation dans la configuration et la gestion de son infrastructure. Bien que cela puisse offrir un contrôle accru sur la sécurité, cela nécessite également des compétences et des ressources pour maintenir un environnement sécurisé.
✔️ Contrôle
- Cloud : Le cloud offre généralement moins de contrôle direct sur l'infrastructure sous-jacente, car les ressources sont gérées par le fournisseur de services. Cela peut limiter la capacité de personnaliser l'environnement selon les besoins spécifiques de l'organisation.
- Open source : En revanche, le déploiement en open source permet un contrôle total sur l'ensemble de l'infrastructure, des logiciels et des données. Cela permet aux organisations de personnaliser chaque aspect de leur système pour répondre à leurs besoins uniques.
Le choix entre le cloud et l'open source pour le déploiement d'un modèle de LLM dépend des préférences et des exigences spécifiques de chaque organisation. Alors que le cloud offre une mise en œuvre rapide et une évolutivité facile, l'open source offre un contrôle plus fin et des coûts à long terme potentiellement plus bas. En pesant les avantages et les inconvénients de chaque option, vous pouvez choisir la solution qui convient le mieux à vos besoins en matière de traitement automatique du langage naturel.
Qu’est-ce que la taille d’un LLM ?
❓Qu’est-ce que le nombre de paramètres d’un modèle ?
Imaginez que vous utilisez un logiciel de traduction en ligne qui vous aide à comprendre des textes dans une langue étrangère. Ce logiciel fonctionne grâce à un modèle de traitement automatique du langage naturel, un peu comme un cerveau virtuel qui comprend et génère du texte.
Pour que ce modèle soit efficace, il doit avoir ce qu'on appelle des "paramètres". Ces paramètres sont essentiellement des variables (ou des poids) que le modèle utilise pour interpréter et produire du langage. Chaque paramètre correspond à une caractéristique spécifique du langage, comme la signification des mots ou la structure grammaticale des phrases.
Le nombre de paramètres dans un modèle indique sa complexité et sa capacité à traiter des tâches linguistiques diverses. Plus il y a de paramètres, plus le modèle peut capturer de nuances et de subtilités dans le langage. Cependant, cela signifie aussi que le modèle nécessite plus de ressources pour fonctionner efficacement.
En résumé, les paramètres d'un modèle de traitement du langage naturel sont les composants clés qui déterminent sa capacité à comprendre et à générer du langage. Un modèle avec un grand nombre de paramètres peut offrir des performances plus élevées, mais nécessitera également des ressources plus importantes.
⏱️ Comment mesure-t-on la vitesse d’un modèle (inférence) ?
L'inférence se réfère à la phase où le modèle est utilisé pour effectuer des tâches spécifiques après avoir été entraîné sur un ensemble de données. Concrètement, cela signifie que le modèle utilise les connaissances qu'il a acquises lors de l'entraînement pour prendre des décisions ou générer des résultats en réponse à de nouvelles données.
Pour mesurer la vitesse d'inférence d'un modèle, on évalue le temps nécessaire au modèle pour traiter une nouvelle entrée et produire une sortie. Par exemple, si vous posez une question à un modèle de LLM et qu'il vous donne une réponse, le temps qu'il lui faut pour effectuer ce processus est ce que l'on mesure.
Cela peut être crucial dans de nombreuses applications. Par exemple, si vous utilisez un modèle de LLM pour répondre aux questions des utilisateurs dans une application de chat en temps réel, vous voulez vous assurer que le modèle peut répondre rapidement pour offrir une expérience fluide à l'utilisateur.
Pour mesurer la vitesse d'inférence, on peut utiliser des outils spécialisés qui chronomètrent le temps nécessaire au modèle pour effectuer chaque prédiction ou génération. Cela nous donne une idée de la rapidité avec laquelle le modèle peut traiter les données et produire des résultats, ce qui est essentiel pour évaluer son utilité dans des applications en temps réel.
🗜 Optimisation : la quantification d’un LLM
La quantification d'un LLM, c'est-à-dire sa conversion en un format plus efficace pour l'inférence, peut également jouer un rôle crucial dans l'optimisation des performances et des coûts. Voici un aperçu des principaux aspects à considérer lors de la quantification d'un modèle de LLM :
Avantages de la quantification :
- Réduction de la taille du modèle : La quantification permet de réduire la taille des modèles en convertissant les paramètres de précision élevée (par exemple, 32 bits) en paramètres de précision inférieure (par exemple, 8 bits). Cela permet d'économiser de l'espace de stockage et de mémoire, ce qui peut être crucial pour le déploiement sur des appareils avec des ressources limitées.
- Amélioration des performances : En réduisant la taille des modèles, la quantification peut également améliorer les performances en termes de temps d'inférence et de vitesse de traitement. Des modèles plus compacts peuvent être chargés plus rapidement en mémoire et exécutés plus efficacement, ce qui est particulièrement avantageux pour les applications en temps réel.
- Compatibilité matérielle accrue : Les modèles quantifiés peuvent être exécutés sur une plus large gamme de matériels, y compris des dispositifs avec des capacités de calcul et de mémoire limitées. Cela ouvre la voie à un déploiement plus flexible sur différents types d'appareils, des smartphones aux serveurs cloud.
Inconvénients de la quantification :
- Perte de précision : La réduction de la précision des paramètres peut entraîner une perte d'informations dans le modèle, ce qui peut affecter ses performances dans certaines tâches. Pour les modèles quantifiés avec une précision inférieure, il peut être nécessaire de compenser cette perte en ajustant d'autres aspects du modèle ou en utilisant des techniques de post-entraînement.
- Complexité de mise en œuvre : La quantification des modèles de LLM peut être une tâche complexe et nécessiter une expertise en ingénierie logicielle. La mise en œuvre de la quantification peut nécessiter des ajustements dans l'architecture du modèle, ainsi que des tests approfondis pour garantir que les performances ne sont pas compromises.
En résumé, la quantification des modèles de LLM offre des avantages significatifs en termes de taille, de performances et de compatibilité matérielle, mais elle nécessite une approche prudente pour minimiser les inconvénients potentiels liés à la perte de précision et à la complexité de mise en œuvre. En comprenant ces considérations, les développeurs peuvent tirer parti de la quantification pour optimiser l'utilisation des ressources matérielles et améliorer les performances des modèles de LLM dans une variété d'applications.
Comment mesurer la qualité d’un modèle
🕵️♂️Benchmark de modèle
L'évaluation des performances d'un modèle à l'aide de benchmarks standardisés peut fournir des indications précieuses sur sa qualité et sa pertinence pour une tâche spécifique. Les benchmarks fournissent un cadre standardisé pour évaluer ces performances et permettent une comparaison équitable entre les modèles.
Plusieurs initiatives et plateformes fournissent des classements régulièrement mis à jour, offrant ainsi une vue d'ensemble des modèles disponibles. Les classements les plus populaires et respectés dans la communauté sont ceux que vous pouvez retrouver sur HuggingFace et qui implémente les différentes techniques d’évaluation :
- Génération de code avec HumanEval : Ce benchmark se concentre sur l'évaluation des capacités des modèles à générer du code informatique à partir de descriptions textuelles en langage naturel. HumanEval
- Discussion avec MTBench : Ce benchmark évalue la capacité des modèles à engager des conversations cohérentes et pertinentes avec les utilisateurs, en tenant compte de facteurs tels que la compréhension du contexte, la fluidité du dialogue et la pertinence des réponses. MTBench
- Raisonnement avec l'AI2 Reasoning Challenge (ARC) : Ce benchmark se concentre sur l'évaluation des capacités des modèles à effectuer des tâches de raisonnement logique et de résolution de problèmes. AI2 Reasoning Challenge
- Questions/Réponses avec MMLU : Le benchmark MMLU se concentre sur l'évaluation des compétences des modèles de LLM dans la compréhension de textes et la réponse à des questions basées sur ces textes. Les modèles sont évalués sur leur capacité à extraire des informations pertinentes à partir de textes complexes et à fournir des réponses précises aux questions posées. MMLU
🛠️Comment installer un LLM ?
Installer un LLM sur une machine locale implique généralement les étapes suivantes :
- Installation de l'environnement de développement : Y compris les bibliothèques Python nécessaires pour exécuter des modèles de LLM, telles que TensorFlow, PyTorch ou HuggingFace Transformers.
- Téléchargement du modèle pré-entraîné ou entraînement du modèle à partir de zéro : En utilisant les ressources matérielles disponibles sur votre machine.
- Configuration et ajustement des paramètres du modèle : Ainsi que des hyperparamètres, pour optimiser les performances en fonction de vos besoins spécifiques.
En suivant ces étapes et en prenant en compte les recommandations matérielles, vous pouvez installer et exécuter efficacement des modèles de LLM sur votre machine locale, offrant ainsi une flexibilité et un contrôle supplémentaires sur vos expériences de développement et de recherche en traitement automatique du langage naturel.
📚Les ressources nécessaires
Comment évaluer les coûts d’utilisation
Évaluer les coûts d'utilisation d'un LLM est crucial pour garantir une utilisation économique et efficace des ressources, que ce soit sur le cloud ou en utilisant des ressources locales. Voici quelques étapes pour évaluer ces coûts :
- Analyse des coûts du cloud : Si vous utilisez un service cloud pour héberger et exécuter votre modèle de LLM, commencez par examiner les tarifs de votre fournisseur cloud. Les fournisseurs de services cloud facturent généralement en fonction du temps d'utilisation des ressources (comme les instances de calcul) et de la quantité de données traitées. Identifiez les tarifs applicables à votre cas d'utilisation spécifique et estimez les coûts en fonction de la fréquence d'utilisation et du volume de données traitées.
- Estimation des coûts matériels locaux : Si vous utilisez des ressources matérielles locales, telles que des serveurs ou des ordinateurs personnels, évaluez les coûts associés à l'achat, à la mise à niveau et à la maintenance de ce matériel. Cela comprend le coût initial d'achat du matériel, ainsi que les coûts récurrents tels que l'électricité, le refroidissement et la maintenance. Tenez compte également du coût du temps passé par le personnel pour configurer et gérer l'infrastructure.
Le token est l’unité de mesure qui mesure la quantité de texte que les applications dites d’IA comme ChatGPT peuvent traiter en une seule fois : la mesure prend en compte les caractères, les espaces et la ponctuation.
Un token est plus qu’un caractère, moins qu’un mot le plus souvent, par exemple :
- Environnemental = 3 tokens : Environ — nemen — tal
- Géographique = 3 tokens : Gé — ograph — ique
- Différent = 1 token : Différent
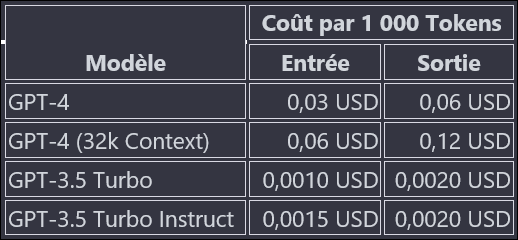
Le tokenizer d’OpenAI permet de comprendre facilement le concept de tokens. La tarification pour l’utilisation de l’API OpenAI dépend du modèle spécifique utilisé et est calculée par tranche de 1 000 tokens. Voici les tarifs en janvier 2024 :
Quelle type de machine pour installer un LLM ?
Le choix de la machine pour installer et exécuter un LLM dépend en grande partie de la taille du modèle et des ressources nécessaires pour son fonctionnement optimal. Voici quelques recommandations générales en fonction de la taille du modèle :
Pour les modèles de grande taille, notamment ceux dépassant les 13 milliards de paramètres (par exemple, le modèle GPT-3 de 175 milliards de paramètres), l'utilisation d'un environnement cloud est souvent recommandée. Ces modèles nécessitent des ressources matérielles considérables en termes de puissance de calcul et de mémoire, ce qui peut dépasser les capacités des machines individuelles.
Cependant, pour les modèles de taille moyenne à grande, en dessous de la barre des 13 milliards de paramètres, il est possible de les exécuter sur des machines individuelles équipées de GPU puissants et de suffisamment de mémoire vive (RAM). Voici les spécifications recommandées pour une machine adaptée :
- GPU avec au moins 10 Go de mémoire vidéo (VRAM), comme la Nvidia RTX 3060 ou équivalent. Les GPU sont essentiels pour accélérer les calculs nécessaires à l'entraînement et à l'inférence des modèles de LLM, grâce à leur architecture parallèle.
- Au moins 64 Go de RAM pour permettre le chargement et la manipulation efficace de grands ensembles de données et de modèles. La mémoire vive est importante pour éviter les goulets d'étranglement lors de l'exécution de tâches intensives en mémoire.
En plus des modèles de grande taille, il existe également des mini-modèles de LLM quantifiés à 1 milliard de paramètres, conçus pour des tâches moins exigeantes en termes de ressources matérielles. Ces mini-modèles peuvent être exécutés efficacement sur des CPU plus modestes, tels que l'Intel i3 ou équivalent, offrant ainsi une option plus légère pour des applications moins intensives en calcul.
En quantifiant un modèle, on réduit le nombre de bits nécessaires pour représenter les paramètres du modèle, ce qui permet d'économiser de la mémoire et d'accélérer les opérations de calcul.
Tableau explicatif :
| Précision | Besoins en mémoire GPU | Exigences en calcul | GPU adapté |
|---|---|---|---|
| Natif (32 bits) | Exigences élevées | Demandes de calcul plus élevées | GPU avec de grandes capacités VRAM et hautes capacités de calcul |
| Quantifié sur 16 bits | Exigences modérées | Demandes de calcul modérées | GPU avec des capacités VRAM modérées et bonnes capacités de calcul |
| Quantifié sur 8 bits | Exigences relativement élevées | Demandes de calcul légèrement plus élevées | GPU avec de grandes capacités VRAM et hautes capacités de calcul |
| Quantifié sur 4 bits | Exigences inférieures | Demandes de calcul inférieures | GPU avec des capacités VRAM limitées |
En utilisant la quantification, les développeurs peuvent adapter les modèles de LLM à une gamme plus large de matériel, en maximisant l'efficacité des ressources disponibles tout en maintenant des performances acceptables.
🧾Les types de licences des LLM open source
Les modèles de LLM open source sont souvent accompagnés de licences spécifiques qui régissent leur utilisation, leur distribution et leur modification. Voici quelques types de licences courants que l'on trouve dans le domaine des LLM open source :
Licence MIT
La licence MIT est l'une des licences open source les plus permissives. Elle permet aux utilisateurs de copier, modifier, distribuer et utiliser le logiciel, y compris les modèles de LLM, à condition que la notice de copyright et la clause de licence soient incluses dans toutes les copies. Cette licence impose peu de restrictions et est souvent choisie pour encourager la collaboration et l'adoption larges du logiciel.
Licence Apache 2.0
La licence Apache 2.0 est similaire à la licence MIT en ce sens qu'elle permet aux utilisateurs de modifier, distribuer et utiliser le logiciel à des fins commerciales et non commerciales. Cependant, elle contient également des dispositions spécifiques pour protéger les droits de propriété intellectuelle du contributeur initial et pour limiter la responsabilité du contributeur.
Licence GPL (General Public License)
La licence GPL est une licence copyleft qui impose des obligations plus strictes aux utilisateurs. Elle stipule que tout logiciel dérivé d'un logiciel sous licence GPL doit également être distribué sous une licence GPL. Cela signifie que si vous utilisez un modèle de LLM sous licence GPL dans votre propre projet, vous devez également distribuer votre projet sous une licence GPL.
Licence Creative Commons
Bien que plus couramment associée aux œuvres artistiques et littéraires, la licence Creative Commons peut également être utilisée pour les modèles de LLM. Les licences Creative Commons offrent différentes options de partage et de réutilisation, allant de la simple attribution à des restrictions plus strictes, telles que l'interdiction de modifications ou l'utilisation à des fins commerciales.
Licence personnalisée
Certains créateurs de modèles de LLM open source choisissent de créer leur propre licence personnalisée pour régir l'utilisation de leur logiciel. Ces licences peuvent être adaptées spécifiquement aux besoins et aux valeurs du créateur et peuvent inclure des dispositions uniques pour la protection des droits d'auteur, la responsabilité et d'autres questions juridiques.
Il est important de lire attentivement les termes de la licence associée à un modèle de LLM open source avant de l'utiliser dans votre propre projet, car cela peut avoir des implications importantes sur la manière dont vous pouvez utiliser et distribuer le logiciel. En comprenant les différents types de licences et leurs implications, vous pouvez choisir la licence qui convient le mieux à vos besoins et à votre situation juridique.
En résumé
Choisir le bon modèle de langage (LLM) pour vos besoins peut être un processus complexe, mais en suivant les critères et les étapes décrites dans cet article, vous pouvez prendre des décisions éclairées. Voici un récapitulatif des points clés à considérer :
- Définir le cas d'utilisation prévu : Comprenez les tâches spécifiques que le modèle doit accomplir.
- Évaluer le domaine des données : Assurez-vous que le modèle est adapté aux types de données que vous utiliserez.
- Exigences en matière de précision : Décidez si vous avez besoin d'un modèle à haute précision ou si une précision modérée suffit.
- Vitesse d'inférence : Considérez l'importance de la latence et de la vitesse de réponse du modèle.
- Besoin de mise à l'échelle : Évaluez la capacité du modèle à gérer le nombre d'utilisateurs ou de requêtes.
- Cloud vs sur site : Choisissez entre la commodité des solutions cloud et le contrôle des solutions sur site.
- Contraintes budgétaires : Analysez les coûts en fonction de l'utilisation des ressources et des fonctionnalités requises.
- Considérations éthiques : Évaluez les biais du modèle et les risques de mauvaise utilisation.
En outre, il est essentiel de comprendre les concepts techniques associés aux LLM, tels que l'entraînement, le fine-tuning, les tokens, l'inférence et la quantification. La comparaison des modèles à l'aide de benchmarks standardisés vous aidera à mesurer la qualité et la performance de chaque modèle.
Ressources supplémentaires
Pour aller plus loin, voici quelques ressources et outils qui peuvent vous être utiles:
- Hugging Face Transformers : Une bibliothèque populaire pour l'utilisation et la fine-tuning de modèles de LLM. Hugging Face
- TensorFlow : Une bibliothèque open source pour le machine learning développée par Google. TensorFlow
- PyTorch : Une bibliothèque open source pour le deep learning développée par Facebook. PyTorch
- OpenAI GPT-3 : Un des modèles de LLM les plus avancés disponibles via une API cloud. OpenAI
- Benchmarks et leaderboards : Consultez des plateformes comme Hugging Face pour les classements et les performances des modèles. Hugging Face Leaderboard
Installer et utiliser un LLM : Guide rapide
Voici un guide rapide pour installer et utiliser un modèle de LLM sur votre machine locale :
1- Installer les bibliothèques nécessaires :
pip install transformers torch
2- Charger un modèle pré-entraîné :
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "gpt-2"
model = AutoModelForCausalLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
3- Utiliser le modèle pour générer du texte :
input_text = "Once upon a time"
input_ids = tokenizer.encode(input_text, return_tensors='pt')
output = model.generate(input_ids, max_length=50)
generated_text = tokenizer.decode(output[0], skip_special_tokens=True)
print(generated_text)
Évaluation des coûts
L'évaluation des coûts d'utilisation d'un LLM est cruciale pour garantir une utilisation économique. Voici un aperçu des étapes pour évaluer ces coûts :
- Analyse des coûts cloud : Examinez les tarifs de votre fournisseur cloud pour l'utilisation des ressources de calcul et de stockage.
- Estimation des coûts locaux : Évaluez les coûts associés à l'achat, la mise à niveau et la maintenance du matériel, ainsi que les coûts récurrents tels que l'électricité et la maintenance.
- Calcul des coûts par token : Utilisez des outils comme le tokenizer d'OpenAI pour estimer la quantité de texte traitée et les coûts associés.
Machines recommandées
Pour les modèles de grande taille (>13 milliards de paramètres), l'utilisation d'un environnement cloud est souvent recommandée. Pour les modèles de taille moyenne à grande, voici les spécifications recommandées pour une machine locale :
- GPU : Au moins 10 Go de VRAM (Nvidia RTX 3060 ou équivalent)
- RAM : Au moins 64 Go de RAM
Pour des modèles plus petits et quantifiés, des machines avec des CPU plus modestes peuvent être utilisées.
Types de licences des LLM open source
Lorsque vous utilisez des modèles de LLM open source, il est important de comprendre les types de licences associées :
- Licence MIT : Permissive, permettant une large utilisation et modification.
- Licence Apache 2.0 : Similaire à MIT, avec des protections supplémentaires pour les droits de propriété intellectuelle.
- Licence GPL : Copyleft, obligeant à distribuer les logiciels dérivés sous la même licence.
- Licence Creative Commons : Options de partage et de réutilisation variées.
- Licence personnalisée : Adaptée spécifiquement aux besoins du créateur.
Choisir et déployer un modèle de LLM adapté à vos besoins nécessite une compréhension approfondie des critères de sélection, des concepts techniques, des coûts et des options de déploiement. En suivant les conseils et les étapes décrits dans cet article, vous serez mieux équipé pour naviguer dans le paysage complexe des LLM et tirer parti de ces puissants outils pour vos projets de traitement automatique du langage naturel.
Cet article est conçu pour servir de guide complet sur la sélection, l'évaluation et le déploiement des modèles de langage de grande taille (LLM). Si vous avez des questions , n'hésitez pas à nous contacter.